Peerz: Decentralized Deep Neural Networks
Publication Date: April 1st 2024
Abstract
Peerz is a peer-to-peer network that facilitates collaborative inference and fine-tuning for large language models (LLMs). This paper provides an in-depth look at the aspects of Peerz, highlighting its decentralized nature, distributed fine-tuning capabilities, and the blockchain-powered incentivization system for the ecosystem providers.
Introduction
Skyrocketing LLM usage faces challenges due to costly infrastructure, inefficiencies, and GPU shortages. Additionally, AI access is often restricted and overregulated globally.
Peerz distributes LLM infrastructure across existing GPUs making AI cheaper, more efficient, and permissionless.
Demand and Availability
The combination of high demand from the AI and gaming industries, alongside supply chain issues (exacerbated by global events such as the COVID-19 pandemic), has led to shortages of GPUs. This shortage affects not only the availability of GPUs for new research and development but also their cost, making them more expensive and less accessible for individual researchers and smaller organizations.
Following Ethereum's transition from a Proof of Work (PoW) model, former Ethereum miners are now in search of new applications for their mining rigs. This shift presents a significant opportunity to repurpose these mining rigs for AI computation, leveraging their substantial processing capabilities for the advancement of artificial intelligence and machine learning projects.
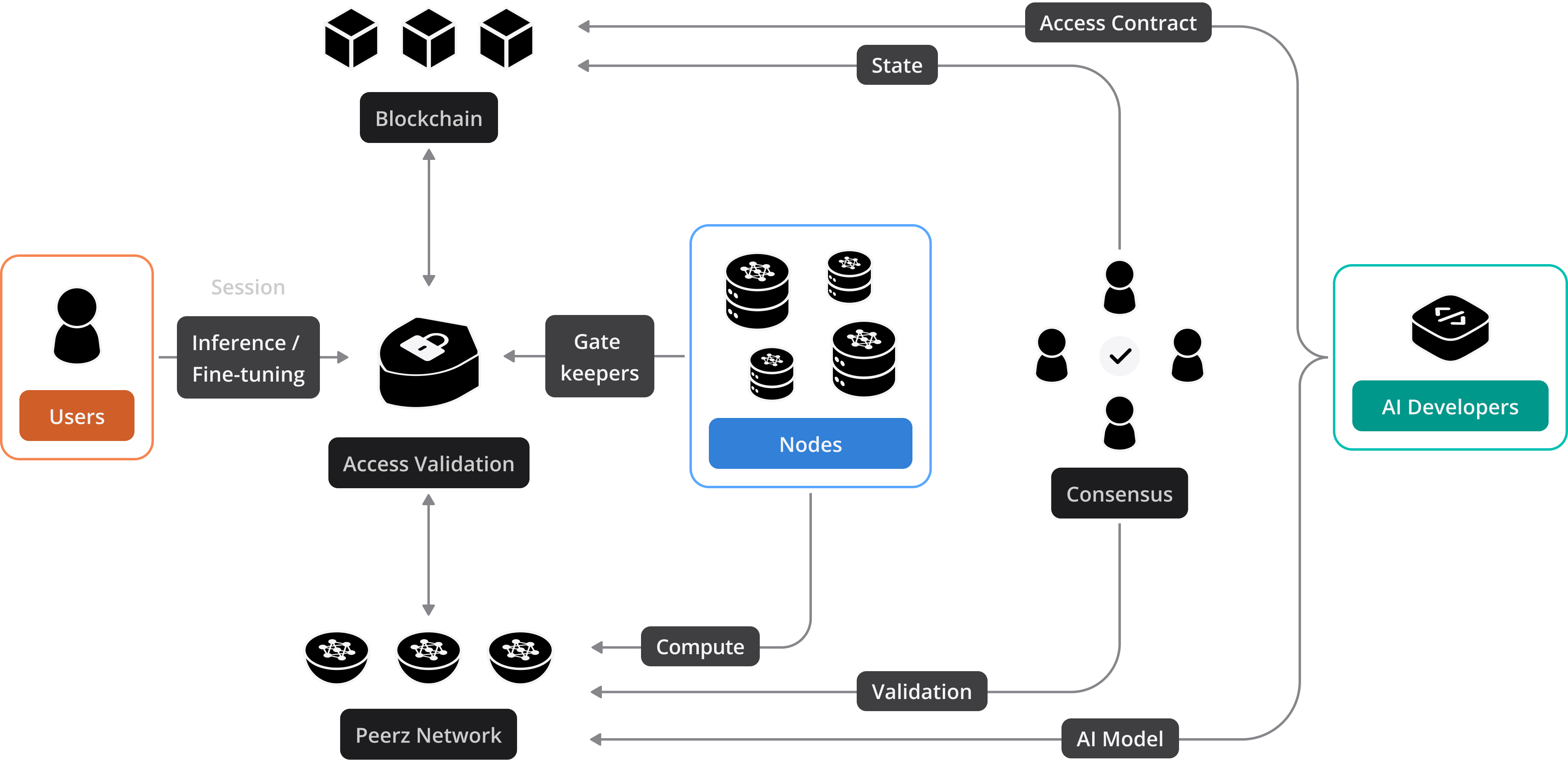
Peerz Network
Peerz operates on a decentralized architecture that enables global collaboration. Nodes across the world can participate in inference and fine-tuning of AI models. This decentralized structure is crucial for driving competition and innovation.
Based on Petals paper, One of Peerz's core technical capabilities is distributed Inference and fine-tuning. Nodes collaboratively fine-tune AI models for specific tasks in a distributed manner. A node hosts a subset of model layers (typically, Transformer blocks) and handles requests from clients. This approach allows for the collective enhancement of model intelligence, additionally this method has been tested to be up to 10 times more efficient than traditional off-loading.
In order to incentivize the open source development of Peerz and participation in different aspects of the Peerz ecosystem, it implements a blockchain-powered incentivization system. The different contributors (known as Providers) are rewarded with $PRZ tokens based on their contribution. This blockchain-driven mechanism ensures transparency, trust, and a fair distribution of rewards while building Peerz, together.
A Technical Deep Dive
Distributed Inference with Subset Model Hosting
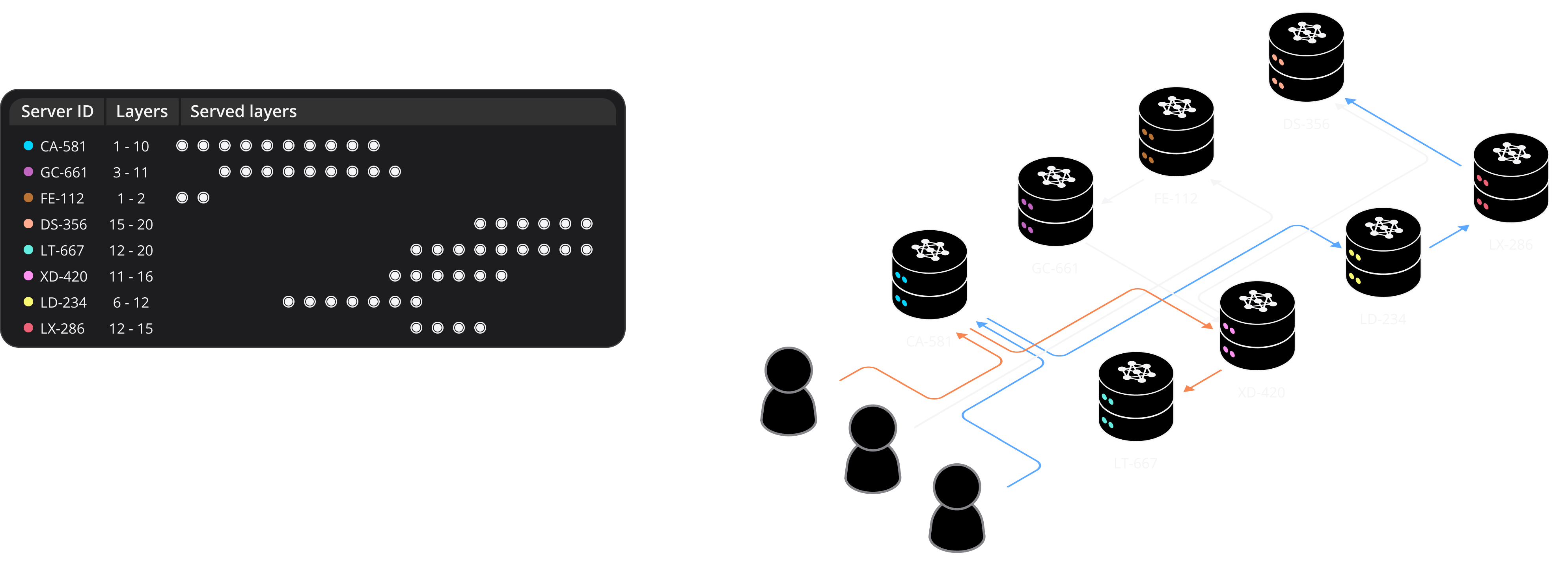
One of the fundamental aspects of Peerz's architecture is the distributed inference and fine-tuning capability, enabled by hosting subsets of large language models (LLMs) on various nodes. This innovative approach overcomes the challenges posed by the immense memory and computational requirements of modern LLMs, such as BLOOM-176B and OPT-175B.
Subset Model Hosting: In the Peerz ecosystem, each participant, whether a node or a client, plays a crucial role. Nodes host subsets of model layers, typically focusing on Transformer blocks. This hosting arrangement allows for efficient inference and fine-tuning without the need for extensive local resources.
Seamless Inference: Clients can form chains of pipeline-parallel nodes to orchestrate the inference of entire LLMs, ensuring that each node processes a specific portion of the input sequence. This approach not only optimizes the inference process but also minimizes latency, resulting in rapid model generation for various tasks.
Fine-Tuning Flexibility: Beyond inference, participants have the flexibility to fine-tune the hosted model subsets. This fine-tuning can be achieved through parameter-efficient training methods such as adapters or prompt tuning. Additionally, participants can train entire layers of the model, further enhancing its task-specific capabilities.
Optimizations for Efficiency: Peerz incorporates several optimizations to ensure efficient distributed inference and fine-tuning. These optimizations include dynamic quantization to reduce memory footprint, prioritizing low-latency connections between nodes, and load balancing mechanisms to distribute computation evenly among participating servers.
By splitting LLMs into manageable subsets and distributing them across nodes, Peerz democratizes access to language models while promoting collaboration and innovation within the AI community. This approach revolutionizes the use of large models for practical applications without the need for prohibitively expensive hardware setups.
Distributed Fine-Tuning
Client-Node Collaboration: In Peerz, clients and nodes collaborate seamlessly in a distributed fine-tuning ecosystem. Clients own trained parameters, while nodes host the original pretrained layers.
Parallel Training: Multiple clients can simultaneously fine-tune models on the same set of nodes without interfering with one another. This parallelism enhances efficiency and scalability.
Optimizations: Peerz incorporates communication optimizations, such as dynamic quantization and weight compression, to streamline the fine-tuning process. These optimizations ensure efficient utilization of model resources.
Communication Optimizations
Reduced Data Transfer: Peerz minimizes data transfer between pipeline stages by implementing dynamic blockwise quantization. This technique significantly reduces bandwidth requirements while maintaining model quality.
Weight Quantization: The platform employs 8-bit mixed matrix decomposition for matrix multiplication, quantizing weights to 8-bit precision. This reduces memory footprint without compromising model performance.
Nodes Collaboration
Reliable Collaboration: Peerz addresses the challenges of nodes joining, leaving, or failing during collaboration. It leverages the Hivemind library for decentralized training and custom fault-tolerant protocols for nodes and clients.
Node Load Balancing: To ensure even distribution of nodes among Transformer blocks, Peerz maximizes model throughput by eliminating potential bottlenecks. Nodes announce their active blocks to a distributed hash table, facilitating load balancing.
Client-Side Routing: Clients efficiently find sequences of servers with minimal latency, ensuring rapid model generation. During fine-tuning, clients split batches among multiple servers, optimizing parallel processing.
Fault Tolerance: In case of server failure during training or inference, Peerz seamlessly replaces the failed server and transfers previous inputs to the replacement server to maintain attention keys and values.
Benchmarks
Petals performance evaluation
In order to comprehensively assess the performance of Petals, their team conducted a series of benchmarks and evaluations, both in emulated and real-world scenarios. These tests shed light on the platform's capabilities and its advantages over alternative approaches.
Comparison with Parameter Offloading
- Benchmark: Comparing with parameter offloading approaches for running large models with limited resources.
- Offloading Setup: Assumes the best possible hardware setup for offloading, including CPU RAM offloading via PCIe 4.0 with 16 PCIe lanes per GPU and PCIe switches for pairs of GPUs.
- Throughput Calculation: Maximum throughput for offloading calculated based on 8-bit model memory usage, PCIe 4.0 throughput, and offloading latency assumptions.
Key Findings:
- Outperforms parameter offloading approaches, especially for single-batch inference.
- For fine-tuning forward passes, offloading becomes competitive only with multiple GPUs and limited networking.
- In most cases, we offer higher throughput than offloading for training tasks.
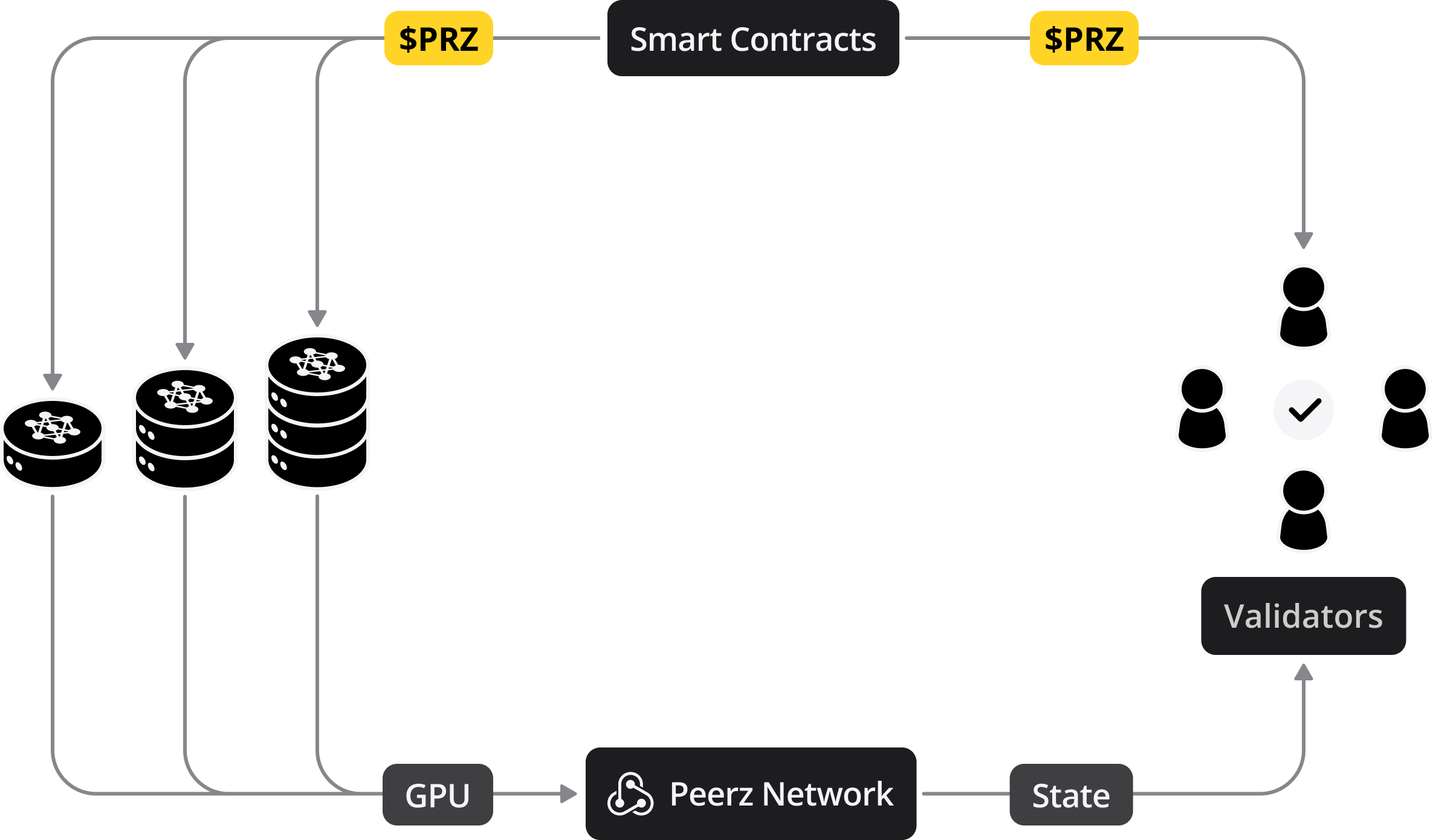
Contribution Weighting and Rewards Distribution
The distribution of rewards takes into account the weight of each contribution, reflecting its value to the ecosystem. The total reward pool is allocated among different roles based on predefined weights , which are periodically reviewed and adjusted to reflect the evolving needs and priorities of the ecosystem.
Equation for Rewards Distribution
The rewards for each role are calculated as follows:
Where:
- is the total rewards pool available in a given period.
- is the weight assigned to role .
- is the sum of weights for all roles, ensuring the distribution is proportionate to the relative importance of each contribution.
Weights and Consensus
Weights are determined through a consensus mechanism that takes into account the current needs of the ecosystem, the scarcity of resources, and strategic priorities. This mechanism ensures that the incentive system remains dynamic, fair, and aligned with Peerz's long-term objectives.
Security and Privacy
Blockchain Security
Peerz employs a robust blockchain infrastructure to secure the incentive system. Blockchain's immutability and cryptographic safeguards protect the integrity of rewards and transactions. GPU providers can trust that their contributions are accurately recorded and rewarded.
Data Privacy
Protecting user data is paramount in Peerz. The platform ensures the privacy of AI model data and any interactions with the models. Data is anonymized and encrypted to prevent unauthorized access. Users can confidently interact with AI models without compromising their privacy.
Model Security
Peerz implements rigorous security measures to safeguard AI models from tampering or malicious attacks. Models are hosted in a secure and controlled environment, with continuous monitoring for any suspicious activity.
Trustless Collaboration
The blockchain-based nature of Peerz fosters trustless collaboration. Participants can engage in collaborative fine-tuning and inference without relying on central authorities.
Conclusion
In conclusion, Peerz introduces a groundbreaking incentive mechanism and leverages blockchain technology to create a secure, privacy-conscious, and competitive ecosystem for AI model improvement. This innovative approach not only drives the evolution of AI models but also ensures the trust and privacy of all participants in the Peerz network.
Peerz's incentive system, blockchain integration, and security measures collectively create a dynamic and trustworthy environment for advancing AI models while preserving user privacy and data security.
Peerz represents a paradigm shift in AI model improvement. Its technical foundations, including decentralization, distributed inference and fine-tuning, and blockchain-driven incentives, are poised to revolutionize the AI landscape. Join the Peerz community and become a part of the decentralized AI revolution, contributing to the advancement of intelligent models.
References
PETALS: Collaborative Inference and Fine-tuning of Large Models